DeepSeek:以創新演算法和更低成本重塑AI領域


作者:Viga Liu
關鍵要點:
· 性能與成本:DeepSeek的R1模型在性能上與OpenAI的O1不相上下,特別在數學和編程領域表現出色,而DeepSeek通過創新演算法實現了更具成本效益的訓練。
· 演算法創新:DeepSeek推出了如MOE、MLA、MTP和RL等開創性的方法,重新定義了AI模型開發的範式。
· NVIDIA的未來:DeepSeek的崛起正在重塑AI行業的估值格局,可能改變市場份額分佈。短期內,NVIDIA的GPU仍佔據主導地位,但DeepSeek的技術路線表明,未來通過演算法優化可能減少對GPU的依賴。
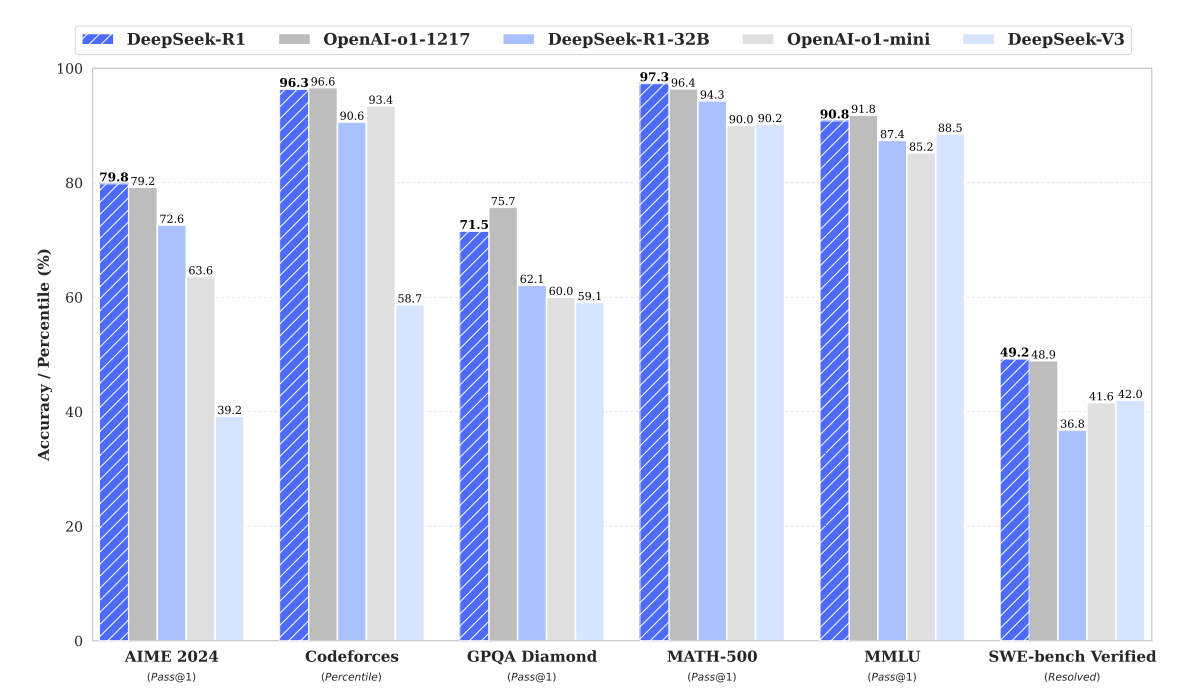
DeepSeek近期發佈的新模型憑藉其在多項標準化測試中的亮眼表現,迅速成為人工智慧領域的焦點,引發了業界的廣泛關注。市場開始重新審視AI領域主要企業的股價,並深入探討DeepSeek的創新可能帶來的市場份額變動及技術路徑調整,這也促使相關企業的市場估值得到重新評估。如下圖所示,DeepSeek的R1模型在多個領域與OpenAI的O1模型表現不相上下,尤其在數學和編程任務中表現尤為突出。然而,在通用知識評估方面,DeepSeek-R1目前尚未實現對OpenAI O1模型的超越。
來源:DeepSeek
在數學競賽AIME 2024上,DeepSeek-R1取得了79.8%的通過率,略高於OpenAI-oo1的79.2%,顯示了其在數學推理方面的競爭力。在編程能力評估中,儘管DeepSeek-R1在Codeforces上達到了96.3%的表現,但仍稍遜於OpenAI-o1的96.6%,表明OpenAI的模型在編程任務中略佔優勢。在複雜數學問題集MATH-500的測試中,DeepSeek-R1以97.3%的準確率領先於OpenAI-o1的96.4%,凸顯了其在數學領域的強勁實力。同樣,在軟體工程基準測試SWE-bench Verified中,DeepSeek-R1解決了49.2%的問題,略高於OpenAI-o1的48.9%,表明兩者在特定工程任務中的表現旗鼓相當。然而,在通用知識測試MMLU中,DeepSeek-R1取得了90.8%的分數,雖接近但未超越OpenAI-o1的91.8%,反映出其在知識廣度上仍存在一定差距。而在GPQA Diamond測試中,DeepSeek-R1以71.5%的準確率顯著低於OpenAI-o1的75.7%,說明DeepSeek-R1在應對高級知識問題方面仍有提升空間。
更低的成本
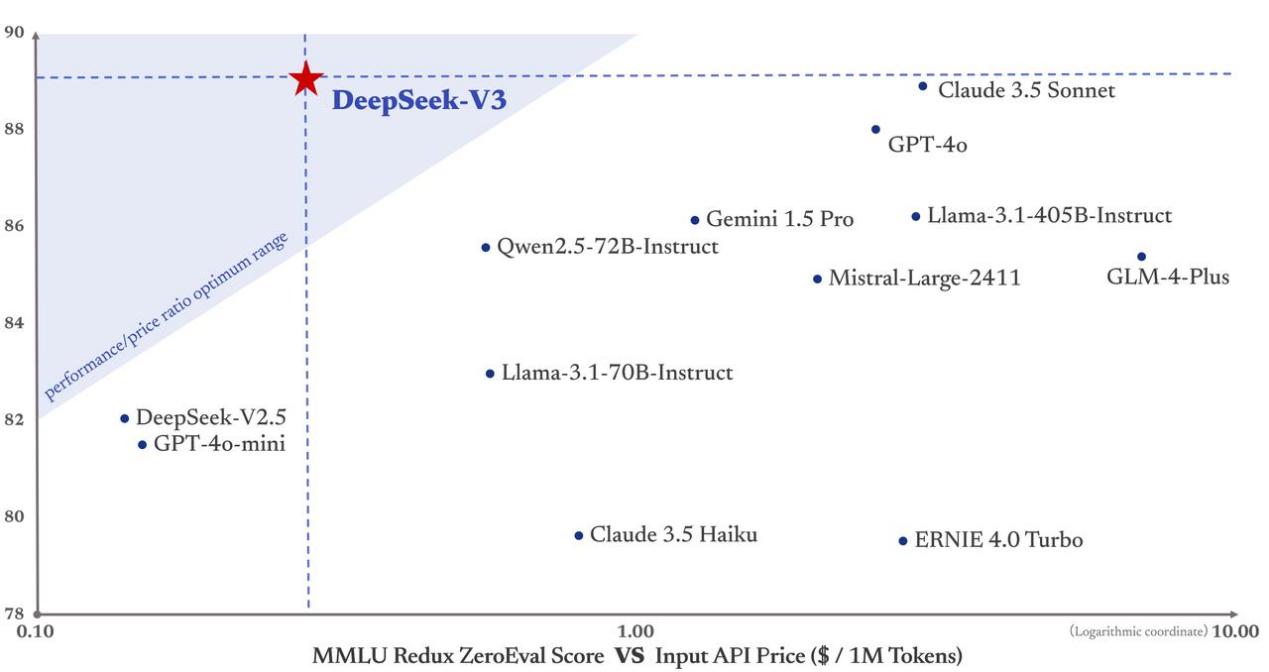
從下表的模型對比中可以看出,DeepSeek V3在成本效益方面具有顯著優勢。其訓練成本僅為558萬美元,使用了2048塊NVIDIA H800 GPU,耗時278萬GPU小時。與其他模型相比,DeepSeek V3以極低的成本脫穎而出。這一成本效益的達成得益於其創新的演算法優化和高效的資源利用,尤其是在DeepSeek V3並未採用最尖端GPU技術(H800並非最新一代產品)的情況下,這一成績尤為引人注目。
根據行業分析公司SemiAnalysis創始人Dylan Patel整理的供應鏈數據,DeepSeek目前已經獲得了約5萬塊NVIDIA晶片,其中包括被禁止出口到中國的H800。目前,尚未被禁運的H20 GPU可能成為H800的替代品,但尚無數據能夠證明H20能否達到相同的性能和效率。如果H20同樣面臨美國的禁運,短期內將沒有直接的晶片替代方案可供選擇。

來源:Deepseek, OpenAI, Anthropic, SemiAnalysis, Tradingkey.com
來源:DeepSeek
演算法創新的分析
儘管DeepSeek在訓練成本上表現出了顯著的低成本優勢,這一結果不可避免地引起了業界的一些質疑。為了揭開這一謎團,深入探討DeepSeek演算法的創新之處是必要的,以此來推論其如何在不犧牲性能的前提下實現成本的節約。
Mixture-of-Experts (MOE)架構
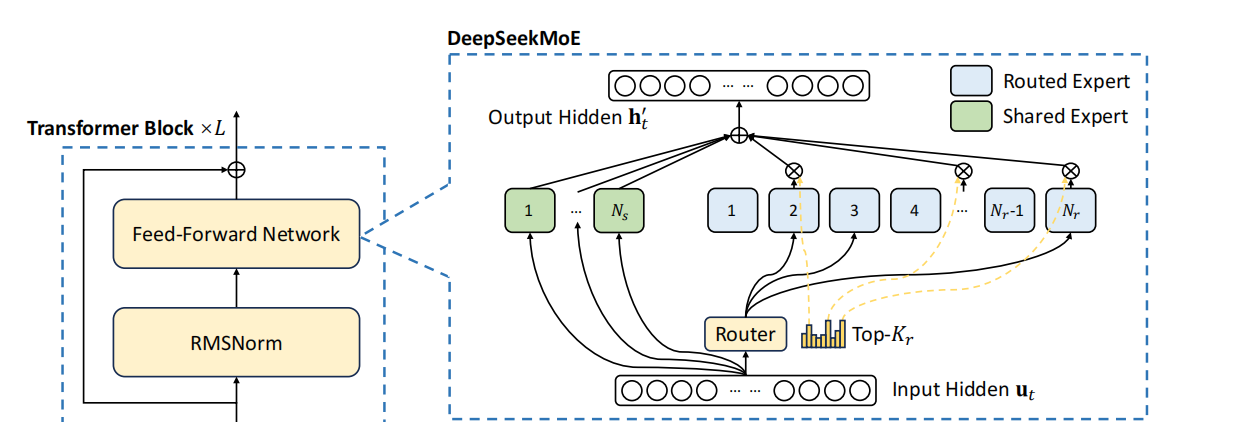
在傳統的大型語言模型訓練中,模型的每一部分都需要處理所有輸入,無論這些輸入是否適合其專業領域。這往往導致模型參數的過度使用或完全閒置,從而造成計算資源的浪費。模型可能需要巨大的計算能力來處理各種類型的數據,但實際上只有一小部分參數被真正用到。由於處理每個輸入時所有參數都必須被啟動,進一步擴展模型會因計算需求和記憶體佔用的急劇增加而變得困難。這正是DeepSeek引入MOE架構的原因。
來源:DeepSeek
細粒度專家分割:DeepSeek通過將專家進一步細分為更小的單元,每個單元專注於特定的數據子集或任務,從而優化了其MOE架構。這樣,每個小專家專注於一個較小的數據子集或任務,這意味著他們可以對其負責的特定領域進行更深入的學習和優化,而不是在所有數據上都表現平庸,同時避免了無效計算,提高了資源利用率。這意味著在相同的計算資源下,可以獲得更高的模型性能。在大型模型中,單一專家網路處理所有類型的數據容易導致過擬合,因為它可能過於專注於學習數據中的噪音。通過細粒度分段,每個專家處理的只是數據的一部分,減少了過擬合的風險,因為他們更專注於捕捉特定領域的模式。通過細粒度專家分段,DeepSeek能夠在不增加參數總數的前提下,提升模型的專業性和效率。
共用專家:DeepSeek的MOE架構中引入了共用專家,用於處理模型中共通的通用知識,這些知識不局限於特定任務。共用知識只需學習一次,便可被所有專家直接調用,避免了重複學習,從而加速處理過程並提升效率。。
負載平衡:負載平衡MOE架構中至關重要,它確保專家之間工作量的均勻分配。在其他MOE模型中,如果負載不均衡,某些專家可能幾乎不被使用。傳統上,負載平衡需要通過引入額外的損失函數來實現,這樣做會增加模型的複雜性和計算開銷,因為需要額外的計算來管理平衡。DeepSeek的方法減少了這部分開銷。DeepSeek的創新在於它通過在Softmax層中引入偏置來動態調整每個專家的工作量分配。Softmax會給每個專家一個概率,概率高的專家更有可能處理當前的任務。偏置值會影響Softmax層的輸出,使得那些負擔過重的專家的概率稍微降低,而那些負擔較輕的專家的概率稍微提高。在訓練過程中,如果發現某個專家處理的tokens過多,可以通過Softmax層中的偏置降低這個專家的選擇概率,使得tokens更均勻地分佈到其他專家。通過這種方式,DeepSeek在不增加模型複雜度和計算開銷的情況下,實現了有效的負載平衡,讓每個專家都能得到合理的工作量,從而提高了模型的整體效率和資源利用率。
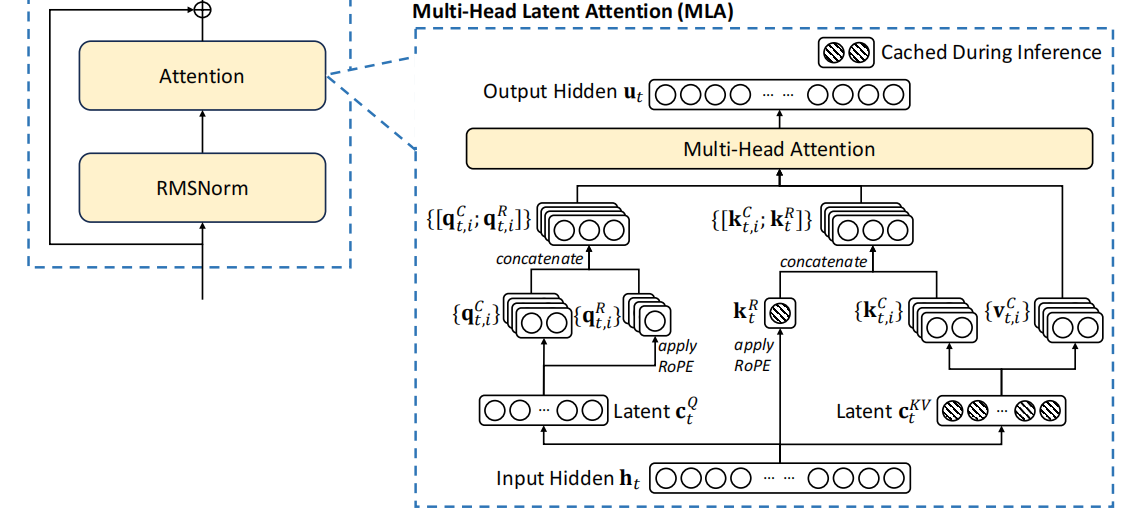
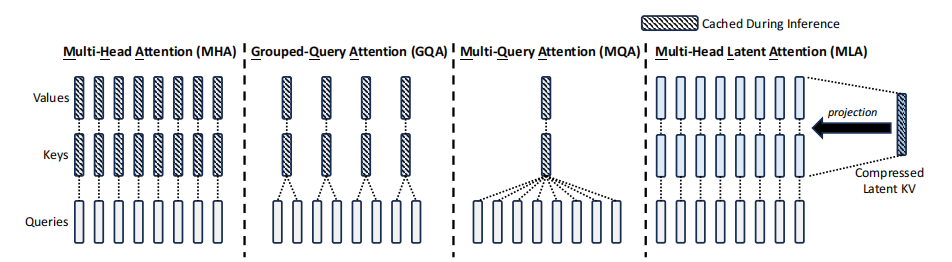
Multi-Head Latent Attention (MLA)
在傳統的注意力機制中,模型相當於逐字閱讀一本書,而MLA則是通過壓縮資訊來快速理解書的要點。DeepSeek開MLA的主要動機在於解決傳統注意力機制在處理大規模數據時的幾個關鍵問題。傳統的多頭注意力機制中需要存儲每個token的K(鍵)、V(值),這在處理長文本或大批量數據時會導致巨大的記憶體需求KV緩存會變得非常龐大,佔據大量的記憶體。在生成每個新token時,傳統方法需要對所有前面的tokens進行計算,這大大增加了計算量,特別是在推理階段。因為計算量大,傳統模型在生成文本時速度較慢,尤其是在處理長序列時。
來源:DeepSeek
記憶體優化:通過低秩分解,MLA將Q(查詢)、K(鍵)、V(值)矩陣壓縮成更小的形式,顯著減少了KV緩存的尺寸。在傳統的多頭注意力機制中,Q、K、V三個矩陣是完整的,高維度的。這意味著它們存儲了所有可能的細節資訊。低秩分解就像是將這三個矩陣拆分成更小的部分,這些部分組合起來能夠近似表示原始矩陣,但只保留了最重要的資訊,減少了存儲需求。
來源:DeepSeek
潛在空間壓縮:將資訊從高維度壓縮到低維度,原始的K和V被映射到一個低維度的“潛在空間”,在這個空間中,數據的表示更簡潔但仍然包含了關鍵資訊。壓縮後的數據更易處理,減少了計算量。矩陣乘法等操作在低維空間中進行,計算速度顯著提高。
Rotary Positional Embedding, RoPE:位置資訊在文本處理中至關重要。傳統模型在數據壓縮或簡化後可能會丟失這一資訊,因為它們依賴於詳細且固定的位置編碼。DeepSeek將RoPE集成到其MLA機制中,以確保即使在數據壓縮後,模型仍能理解位置資訊。RoPE通過旋轉矩陣對位置資訊進行編碼,其中每個token的位置由旋轉角度表示,而這一角度隨位置變化。這種方法能夠在壓縮空間中捕捉“詞與詞之間的距離”,而無需為每個位置存儲位置向量,從而優化了記憶體使用並降低了計算複雜度。在生成新token時,RoPE通過保留上下文中的位置關係,幫助模型更準確地預測下一個詞的位置。
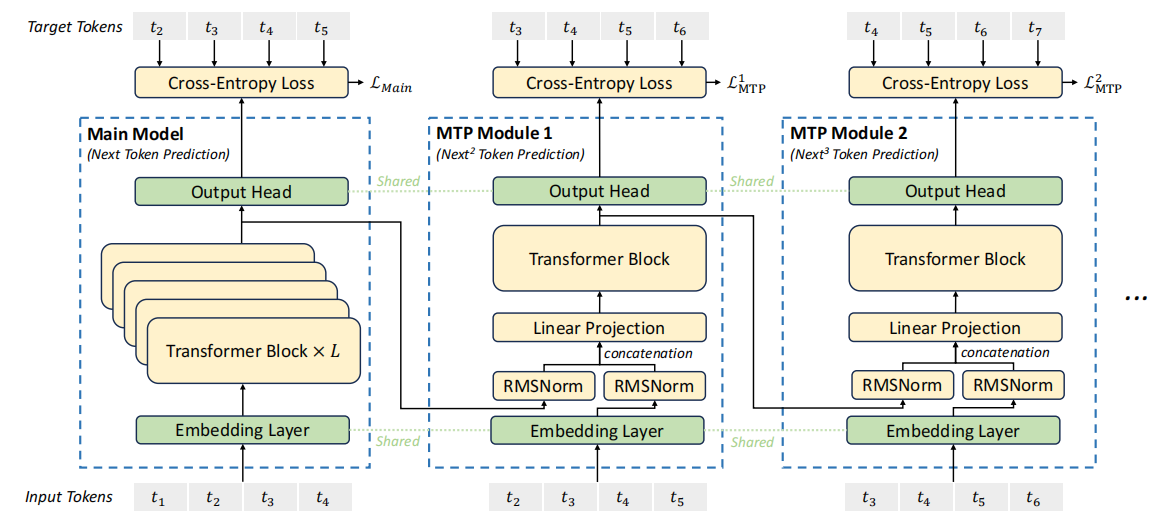
Multi-Token Prediction (MTP)
大語言模型通常是自回歸,即一次只生成一個token,一輪訓練或推理需要進行多次操作才能完成對一句話或一段文字的處理,訓練過程緩慢。DeepSeek創新的MTP改變了傳統的訓練和推理方式。
來源:DeepSeek
並行預測:每一個訓練步驟,模型同時預測多個未來的tokens,而不是一個。這減少了訓練步驟,因為一輪訓練可以處理更多的資訊。
Speculative Decoding:預先生成多個可能性並快速驗證,減少了等待時間,來優化推理速度。在驗證過程中,模型可能使用之前已經計算好的資訊(KV緩存),避免重複計算,提高速度。
Mask機制:通過在注意力層中使用mask,確保模型在預測未來tokens時,不能看到那些tokens後面的內容,維持了序列的因果關係。
Reinforcement Learning (RL)
Supervised Fine-Tuning (SFT)是訓練語言模型的一個常見方法,通過標注數據對預訓練的語言模型進行進一步訓練,在OpenAI的模式中,SFT是post-training的一部分。首先進行大規模的預訓,然後通過SFT來細化模型的輸出,使其更符合特定任務的需求。接著,可能會使RL進行模型的對齊,以確保模型的輸出符合人類的偏好。DeepSeek提出了一種新的後訓練方法,認為在增強模型的推理能方面,SFT並非必要,而直接使用RL。
替代SFT:模型通過與環境的互動來學習和改進,而不是依賴於人工標注的大量數據。這減少了對數據收集和標注的依賴,減少了數據標注過程中的勞動力成本。
Multistage Training:採用了多階段的訓練策略,先進行大規模的預訓練,然後利用RL進行後期的優化。這種方法允許在不同階段利用不同類型的學習機制,增強模型的推理和理解能力。
冷啟動數據:使用已有的模型生成數據來訓練新的模型或增強現有模型。這是一種通過Bootstrapping來擴展數據集的方法,減少了對外部新數據的依賴,降低了數據成本。
挑戰Scaling Law:傳統上模型的性能通常會隨著模型規模的線性或近似線性增長,即規模越大,性能通常越好,但這種增長趨勢是有限的,可能會達到一個飽和點。但DeepSeek的R1模型通過RL展示了湧現能力,隨著模型規模的增加,某些能力或性能會突然或非線性地顯著提升,而不是簡單地逐步改善。這些能力在較小的模型中可能表現得並不明顯,但在大規模模型中突然湧現出驚人的效果。
DeepSeek的創新在於它不僅僅通過增加模型規模來提升性能,還通過不同的學習方法(如RL)來激發模型潛在的能力。這種方法可能在傳統的Scaling Law中沒有被充分考慮。如果性能的提升不是線性的,那麼在一定的規模下,通過創新的訓練方法,可能不需要無限增加模型規模就能獲得顯著的性能提升,這對於資源利用效率有著積極的影響。DeepSeek的創新不僅帶來了性能上的突破,還提供了更具成本效益的策略,使人工智慧開發更加普及。這對投資者和AI從業者來說無疑是一個好消息。
值得關注的是DeepSeek的技術創新不是憑空而來,而是建立在Google、Meta以及學術界多年研究的基礎之上。但DeepSeek針對需求進行了獨特優化。他們在模型架構、訓練和推理方面進行了系統性改進。例如,DeepSeek對穀歌的“Switch Transformers”中MOE進行了優化,採用了細粒度的專家分割和共用隔離機制。同時,受Meta的“Reformer”啟發,DeepSeek開發MLA通過潛在空間壓縮和低秩分解解決了記憶體問題。這些創新激發了行業內對演算法研究的進一步興趣,我們可以預見,在不久的將來,更多高效的人工智慧模型將湧現。開源模型類似Meta的Llama等可能會採用類似的演算法,從而推動AI技術的進一步發展。
OpenAI對模型蒸餾的指控
在討論DeepSeek的成本優勢時,OpenAI提出了一種可能性,即DeepSeek可能採用了模型蒸餾技術。這種方法通過從一個大型、複雜的“教師”模型中提煉知識到一個較小、更高效的“學生”模型中,以實現性能的保留和計算資源的節約。DeepSeek尚未對這一問題做出回應。如果OpenAI基於這一懷疑決定不給DeepSeek提供API訪問許可權,那麼DeepSeek的模型訓練和推理過程可能受到影響。
即便OpenAI限制DeepSeek的訪問, DeepSeek已經通過其獨特的演算法創新,展示了其可以在不依賴外部模型數據的情況下,實現高效訓練和推理的能力,儘管會製造些困難,但對模型的進一步開發並不會因此完全停滯。
繞過NVIDIA CUDA的可能
DeepSeek已經在實踐中實施了通過定制的PTX(Parallel Thread Execution)指令和自動調優通信塊大小的優化方法。這一策略的核心在於繞過CUDA的高級介面,直接與GPU的底層硬體進行交互。CUDA通常提供了更高層次的抽象,使得開發者可以更容易地編寫GPU加速的程式,CUDA會通過編譯器將代碼轉換為PTX,然後再由GPU硬體執行。DeepSeek通過直接使用PTX指令,能夠繞過這一層抽象,從而實現對硬體資源的更精細控制,減少了不必要的中間步驟,實現高效的模型訓練和推理。
儘管如此,短期內還是沒有辦法完全脫離NVIDIA的生態系統,CUDA已經成為了GPU編程的事實標準,廣大開發者已經適應此生態,轉向非NVIDIA的GPU確實需要重建軟體堆疊,耗時間也費錢,特別是在沒有CUDA的情況下要達到類似的性能。
對NVIDIA的影響
短期影響:NVIDIA在AI計算領域仍然佔據主導地位。例如,現在雖然可以在Amazon Bedrock和Amazon SageMaker AI中部署DeepSeek-R1模型,但NVIDIA的GPU仍然在這些平臺上扮演著關鍵角色,顯示了短期內對其硬體的持續依賴。像Meta、微軟、穀歌和亞馬遜這樣的科技巨頭計畫在2025年大幅增加AI資本支出,其中Meta預計為600-650億美元,微軟為800億美元,穀歌為750億美元(其中30%用於NVIDIA GPU),亞馬遜為1000億美元。這強調了對於高性能計算資源的持續需求,特別是在數據中心端,NVIDIA的GPU在性能、生態系統支持和市場認可度上都處於領先地位,這意味著在AI計算需求繼續增長的背景下,NVIDIA的市場份額和股價在短期內不會受到重大威脅。
演算法優化的影響:從長遠來看,DeepSeek展示的通過演算法優化來提升AI模型效率的策略,確實可能對NVIDIA產生負面影響。如果大廠商轉向通過優化演算法而不是單純增加計算能力來實現AI性能的提升,這將減少對高端GPU的需求。特別是當開源和創新演算法被廣泛採用時,市場對NVIDIA專有硬體的依賴可能會減弱。雖然目前各大廠商聲稱不會減少對算力資源的投資,但隨著時間的推移,市場對算GPU製造商的選擇範圍擴大,可能會導致NVIDIA的市場份額逐漸受到侵蝕。
市場對未來增長的預期:NVIDIA目前股價的估值是基於對2025年強勁增長的預期,EPS增長預測在30%-50%之間。低於這一水準的業績都可能使其股價下調。市場對2025年之後增長軌跡可持續性的擔憂日益加劇,摩根士丹利將NVIDIA GB200的出貨量預測從3萬至3.5萬件下調至2萬至2.5萬件,這可能對市場產生300億至350億美元的影響。這一調整反映了市場對微軟資本支出增長放緩、AI基礎設施生態系統的發展以及關於大語言模型長期效率問題的擔憂,導致對英偉達增長前景的看法更加保守。
本地計算與移動端的潛力: 由於AI計算需求之前集中在數據中心,伺服器和雲計算公司因此受益。但隨著如DeepSeek等公司推動AI模型變得更加高效,有可能將這一需求轉移到本地設備,如個人電腦、平板電腦和智能手機。這種轉變意味著AI不再只是數據中心的專利,而是可以普及到消費者手中。蘋果等消費電子廠商,如果AI模型能在其設備上提供引人注目的功能,這將極大地擴大AI的使用範圍,增加對高效、AI友好的消費類設備的需求。