

DeepSeek: Challenging the AI Landscape with Innovative Algorithms and Lower Costs


By Viga Liu
Key Takeaways:
· Performance & Cost: DeepSeek's R1 model rivals OpenAI's O1, excelling in math and coding, with DeepSeek V3 offering cost-effective training through innovative algorithms.
· Innovations: DeepSeek introduces groundbreaking methods like MOE, MLA, MTP, and RL, redefining AI development.
· NVIDIA's Future: DeepSeek's rise is reshaping AI sector valuations, potentially altering market shares. Short-term dominance for NVIDIA's GPUs, but DeepSeek's approach suggests a future where algorithm optimization might lessen GPU dependency.
DeepSeek's recent released models have rapidly become a focal point in the AI industry due to their outstanding performance across multiple standardized tests, garnering widespread attention from the sector. The market has begun to reassess the stock prices of major companies in the AI field, considering the potential redistribution of market shares and shifts in technological trajectories that DeepSeek's innovations might bring. This has led to a reevaluation of the market valuations of related companies. As illustrated in the figure below, DeepSeek's R1 model performs comparably to OpenAI's O1 model across various domains, particularly excelling in mathematics and programming tasks. However, in general knowledge assessments, DeepSeek-R1 has not surpassed the OpenAI O1 model.
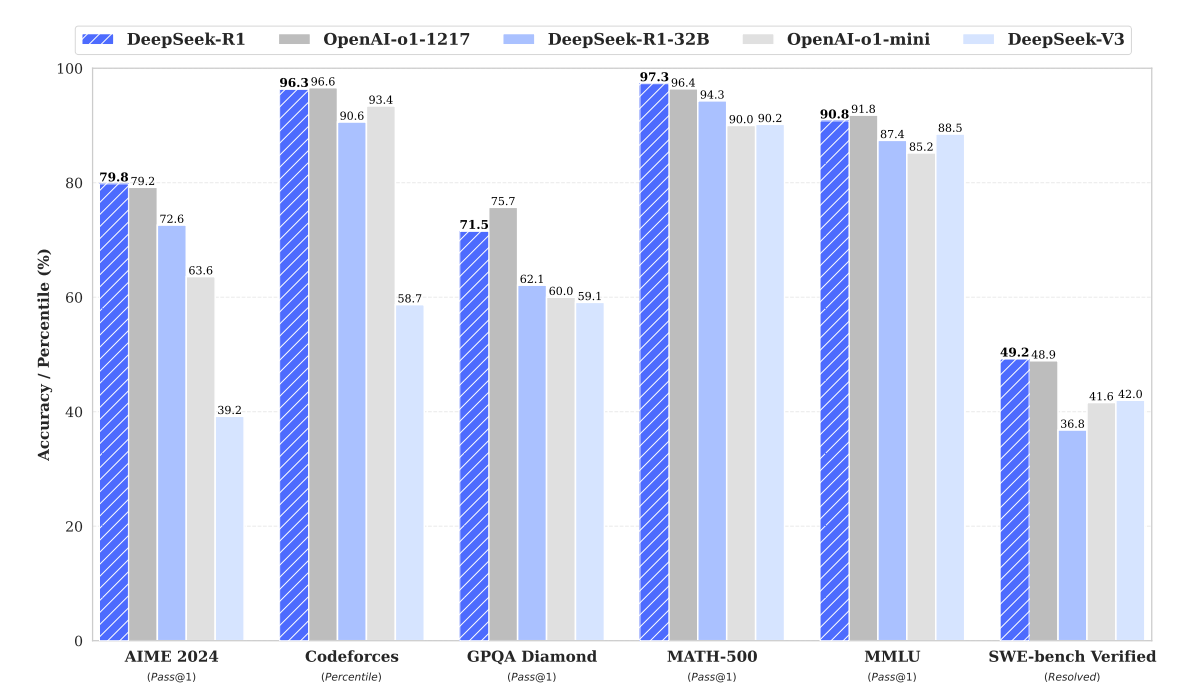
Source: DeepSeek
At the AIME 2024 mathematics competition benchmark, DeepSeek-R1 achieved a pass rate of 79.8%, slightly higher than OpenAI-1-o1's 79.2%, demonstrating its competitiveness in mathematical reasoning. In programming capability evaluations, although DeepSeek-R1 reached 96.3% on Codeforces, it was slightly behind OpenAI-o1's 96.6%, indicating that OpenAI's model has a slight edge in programming tasks. On the complex mathematical problem set MATH-500, DeepSeek-R1 led with an accuracy rate of 97.3% compared to OpenAI-o1's 96.4%, showcasing its strong performance in mathematics. Similarly, in the software engineering benchmark SWE-bench Verified, DeepSeek-R1 solved 49.2% of the problems, compared to OpenAI-o1's 48.9%, indicating comparable performance in specific engineering tasks. However, in the general knowledge test MMLU, DeepSeek-R1 scored 90.8%, close but not surpassing OpenAI-o1's 91.8%, reflecting a gap in the breadth of knowledge. In the GPQA Diamond test, DeepSeek-R1's accuracy rate of 71.5% was significantly lower than OpenAI-o1's 75.7%, suggesting that DeepSeek-R1 still has room for improvement in handling advanced knowledge questions.
Lower Cost
From the model comparison in the table below, it's clear that DeepSeek V3 has a significant edge in cost efficiency. Its training was completed at a cost of just $5.58 million, utilizing 2,048 NVIDIA H800 GPUs over 2.78 million GPU hours. When compared with other models, DeepSeek V3 stands out for its remarkably low cost. This cost efficiency is achieved through innovative algorithm optimization and efficient resource utilization, especially noteworthy given that the H800 GPUs DeepSeek V3 employs are not the most cutting-edge technology available.
However, according to supply chain data compiled by Dylan Patel, the founder of industry analysis firm SemiAnalysis, DeepSeek has managed to secure about 50,000 NVIDIA chips, including the H800, which is banned to export to China. Currently, the H20 GPU, which has not been embargoed, could potentially serve as a substitute for the H800, but there's no data yet to support its performance and efficiency in this role. Should the H20 also face an embargo from the US, there would be no immediate chip alternative available.

Source: Deepseek, OpenAI, Anthropic, SemiAnalysis, Tradingkey.com
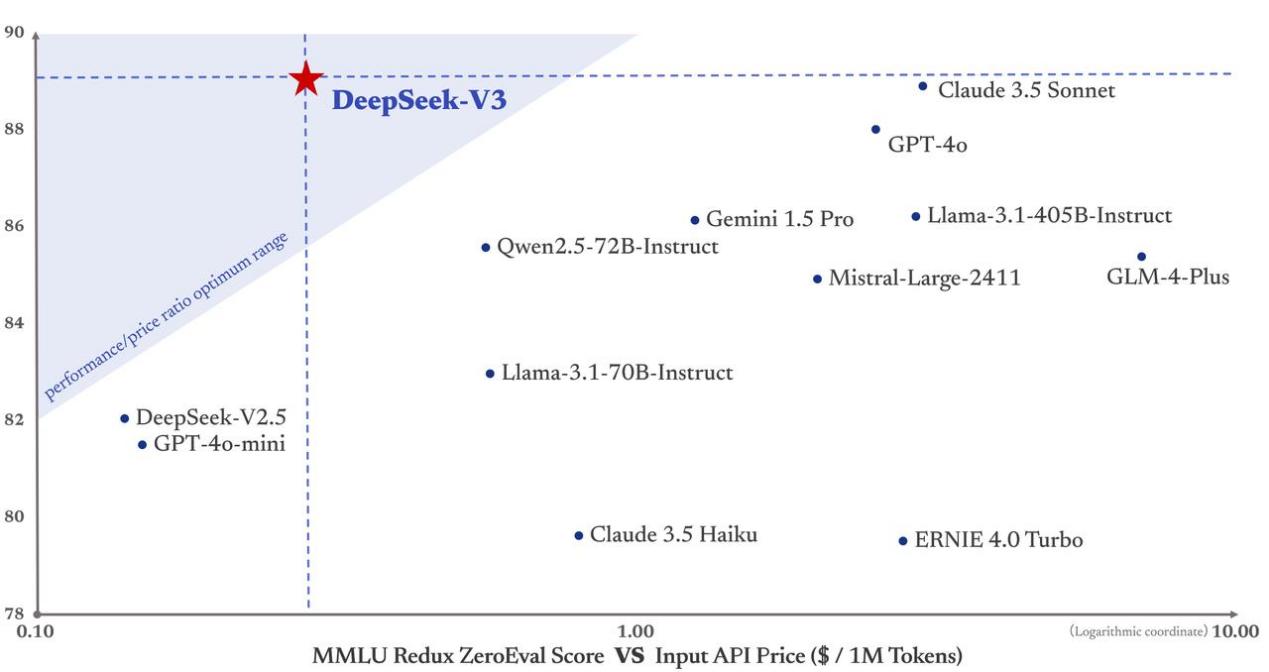
Source: DeepSeek
Algorithm Innovation Analysis
Despite DeepSeek demonstrating a significant cost advantage in training, this result has inevitably raised some skepticism within the industry. To unravel this mystery, it's crucial to delve into the innovations of the DeepSeek algorithm, to infer how it achieves cost savings without compromising performance.
Mixture-of-Experts (MOE) Architecture
In traditional large language model training, every part of the model is required to process all inputs, regardless of whether they suit its expertise. This often leads to overuse or complete idleness of model parameters, resulting in a waste of computational resources. Models might require vast computational power to handle various types of data, yet only a small fraction of parameters is actually needed. Since all parameters must be activated to process each input, scaling the model further becomes challenging due to the explosion in computational demand and memory usage. This is where DeepSeek introduces the MOE architecture.
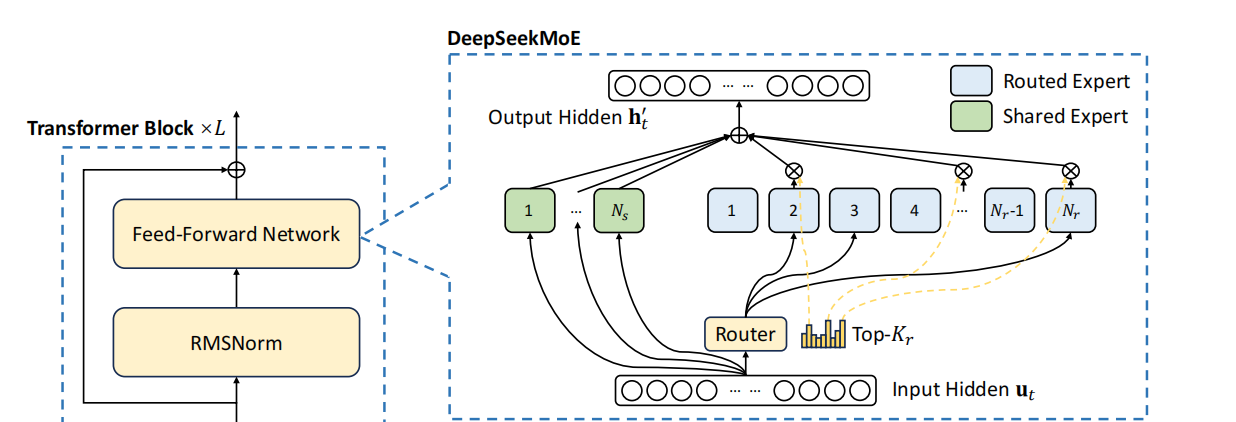
Source: DeepSeek
Fine-Grained Expert Segmentation: DeepSeek further refines its MOE by breaking down experts into smaller units, each focusing on a specific data subset or task. This specialization enhances learning depth within each domain, avoiding mediocre performance across all data. It improves resource utilization by reducing inefficient computations, leading to better model performance with the same resources. In large models, this segmentation minimizes overfitting by allowing experts to concentrate on relevant patterns, not noise, without increasing the total parameter count.
Shared Expert: DeepSeek's MOE architecture includes shared experts that handle general knowledge used across the model, not tied to specific tasks. This knowledge, learned once, is directly utilized by all experts, eliminating redundant learning, which in turn accelerates processing and boosts efficiency.
Load Balancing: Crucial for MOE, load balancing ensures even workload distribution among experts, akin to workload management in a company. DeepSeek innovates by reducing the complexity and cost associated with traditional load balancing methods, which rely on additional loss functions. Instead, DeepSeek dynamically adjusts expert workloads via bias in the Softmax layer, where the probability of selecting an expert is tweaked based on current load. If an expert is overused, its selection probability is decreased, promoting a balanced distribution of tokens. This approach enhances efficiency without adding to model complexity.
Multi-Head Latent Attention (MLA)
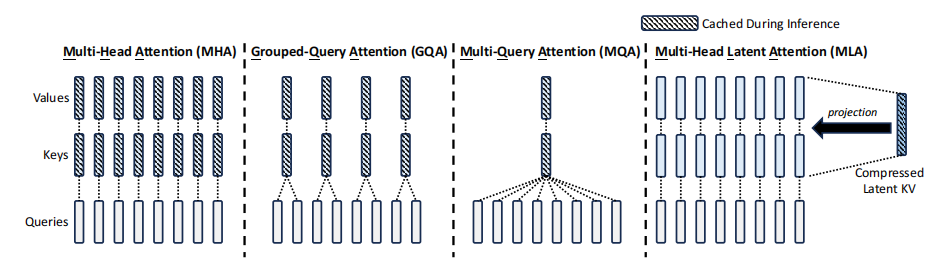
DeepSeek developed MLA to address several key issues with traditional attention mechanisms when handling large volumes of data. The conventional Multi-Head Attention (MHA) requires storing keys (K) and values (V) for each token, leading to substantial memory demands, especially with long texts or large datasets. This results in a huge KV cache that consumes a lot of memory. Moreover, generating each new token involves calculating against all previous tokens, significantly increasing computational load, particularly during inference, which slows down text generation, especially for long sequences.
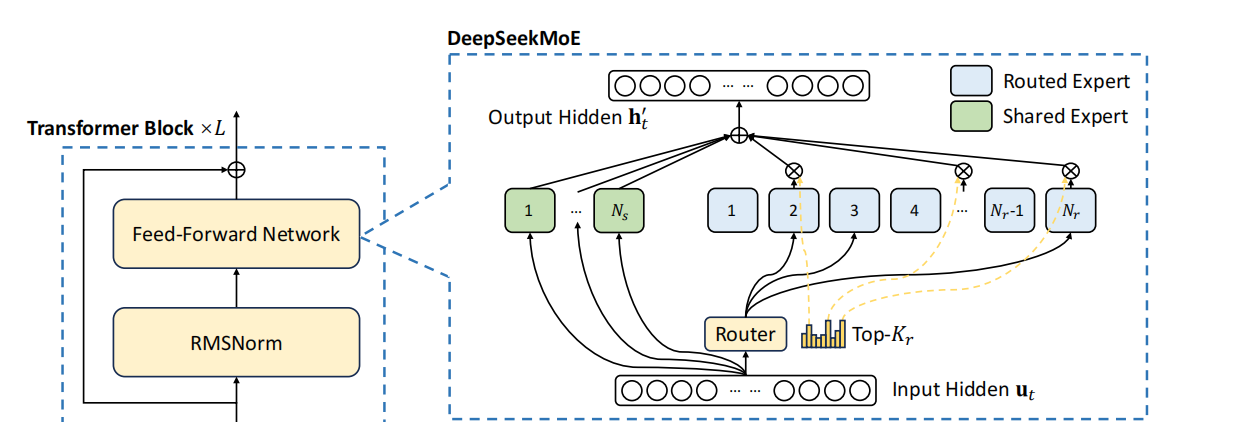
Source: DeepSeek
Memory Reduction: MLA uses low-rank decomposition to compress Q, K, and V matrices, significantly reducing the KV cache size. This simplifies the data by retaining only crucial information, allowing for more efficient memory use and lower computation complexity.
Source: DeepSeek
Latent Space Compression: By mapping K and V to a lower-dimensional latent space, MLA simplifies data representation, cutting down on computation while preserving key information.
Rotary Positional Embedding (RoPE): Position information is crucial in text processing. Traditional models might lose this information after data compression or simplification since they rely on detailed, fixed position encodings. DeepSeek integrates RoPE into its MLA mechanism to ensure positional understanding even after data compression. RoPE encodes position information through a rotation matrix, where each token's position is represented by the rotation angle, which varies with position. This method captures the "distance between words" in the compressed space without needing to store position vectors for each location, optimizing memory usage and reducing computational complexity. When generating new tokens, RoPE helps the model predict the next word's position more accurately by preserving contextual positional relationships.
Multi-Token Prediction (MTP)
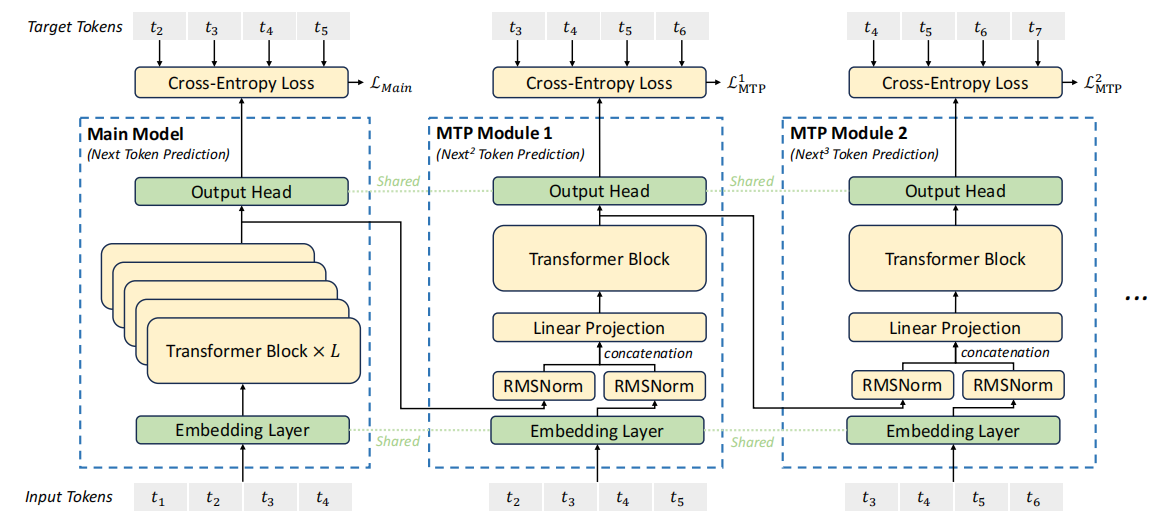
Traditionally, models operate in an auto-regressive manner, generating one token at a time, which slows down training and inference as multiple operations are needed to process a sentence or paragraph. DeepSeek's innovative MTP changes this approach.
Source: DeepSeek
Parallel Prediction: Instead of predicting one token per step, MTP predicts multiple future tokens in each training step. This reduces the number of training steps because more information is processed in a single go.
Speculative Decoding: This technique involves generating multiple potential outcomes upfront and then quickly verifying them, which speeds up inference by minimizing wait times. Here, the model leverages pre-calculated information (KV cache) to avoid redundant computations, enhancing efficiency.
Mask Mechanism: By employing masks in the attention layers, MTP ensures the model doesn't peek at future tokens during prediction, preserving the causal relationship within the sequence.
Reinforcement Learning (RL)
Supervised Fine-Tuning (SFT) is a common approach for refining pre-trained language models with labeled data, acting as part of post-training in the OpenAI framework. It follows large-scale pre-training with a phase to tailor model outputs to specific tasks, sometimes followed by RL to align outputs with human preferences. DeepSeek, however, introduces a novel post-training method, suggesting that for enhancing reasoning abilities, SFT might not be necessary; instead, they advocate for direct use of RL.
Replacing SFT: Instead of relying on extensive manually labeled data, the model learns and improves through interaction with its environment. This reduces dependency on data collection and annotation, cutting down on labor costs associated with data labeling.
Multistage Training: This strategy involves initial large-scale pre-training followed by optimization through RL. It leverages different learning mechanisms at different stages to boost reasoning and comprehension capabilities.
Cold-start Data: Existing models are used to generate data for training new models or enhancing current ones. This 'bootstrapping' method expands datasets without external data, reducing costs.
Challenging Scaling Law: Traditionally, model performance scales linearly or near-linearly with size, but there's a saturation point. DeepSeek's R1 model, through RL, demonstrates emergent abilities where certain capabilities significantly improve non-linearly with scale, not just incrementally. These abilities might be subtle in smaller models but become pronounced in larger ones.
DeepSeek innovates by enhancing performance through techniques like RL, not just by increasing model size. This approach challenges traditional scaling laws, suggesting significant performance gains can be achieved with innovative training at certain scales, improving resource efficiency. It encourages exploring different training methods and architectures for non-linear improvements. DeepSeek's innovations have led to performance breakthroughs and cost-effective strategies, making AI development more accessible. This is exciting for investors and AI professionals.
These innovations build on research from Google, Meta, and academia but are uniquely optimized for DeepSeek's needs. They've systematically improved model architecture, training, and inference. For example, DeepSeek refined MOE from Google's "Switch Transformers" with fine-grained expert segmentation and shared isolation. MLA, inspired by Meta's "Reformer", uses latent space compression and low-rank decomposition to tackle memory issues. These innovations have sparked further interest in algorithmic research within the industry, and we can anticipate the emergence of even more efficient AI models in the near future. Open-source models such as Meta's Llama may adopt similar algorithm, pushing AI technology forward.
OpenAI's Accusation of Model Distillation
OpenAI has accused DeepSeek of possibly using model distillation to achieve cost advantages, where knowledge from a large model is transferred to a smaller one. DeepSeek hasn't responded, and if OpenAI restricts API access, it could affect DeepSeek's operations. However, DeepSeek has shown it can train and infer efficiently without external data, suggesting development won't stop entirely.
Possibility of Bypassing NVIDIA's CUDA
DeepSeek has implemented optimizations using custom PTX (Parallel Thread Execution) instructions and automatically tuned communication block sizes. This approach focuses on bypassing CUDA's high-level interface to directly interact with the GPU's hardware. CUDA offers a higher level of abstraction, making it easier for developers to write GPU-accelerated programs. CUDA converts the code into PTX through the compiler and then executes it by the GPU hardware. By directly using PTX instructions, DeepSeek gains finer control over hardware resources, cutting out unnecessary intermediary steps for efficient model training and inference. However, in the short term, completely moving away from NVIDIA's ecosystem isn't feasible. CUDA has become the de facto standard for GPU programming, and the broad developer community is accustomed to this ecosystem. Shifting to non-NVIDIA GPUs would require rebuilding the software stack, which is time-consuming and costly, especially to achieve similar performance without CUDA.
Impact on NVIDIA:
Short-term Influence: Despite the ability to deploy DeepSeek-R1 on platforms like Amazon Bedrock and Amazon SageMaker AI, NVIDIA's GPUs remain crucial, highlighting ongoing short-term reliance on its hardware. Major tech giants like Meta, Microsoft, Google, and Amazon are planning significant AI CapEx increases in 2025, with Meta at $60-65 billion, Microsoft at $80 billion, Google at $75 billion (with 30% for NVIDIA GPUs) and Amazon at $100 billion. This underscores the sustained demand for high-performance computing resources, especially in data centers, where NVIDIA leads in performance, ecosystem support, and market recognition, securing its market share and stock price in the near term.
Algorithm Optimization Impact: Long-term, DeepSeek's strategy of enhancing AI model efficiency through algorithm optimization could negatively affect NVIDIA. If companies shift towards improving AI performance through algorithms rather than increasing computational power, the demand for high-end GPUs might decrease. With the adoption of open-source and innovative algorithms, reliance on NVIDIA's proprietary hardware could lessen. Although major players currently maintain their investment in compute resources, over time, as options expand, NVIDIA's market share might erode.
Market Expectations for Future Growth: NVIDIA's stock valuation is predicated on expectations of robust growth in 2025, with EPS growth forecasts between 30% - 50%. Any performance below this could adjust its stock price downward. Concerns are rising about the sustainability of this growth trajectory beyond 2025, highlighted by Morgan Stanley's reduction in NVIDIA GB200 shipment forecasts from 30,000-35,000 to 20,000-25,000 units, potentially impacting market value by $30-35 billion. This adjustment reflects worries over slower CapEx growth at Microsoft, the developing AI infrastructure ecosystem, and questions about the long-term efficiency of LLMs, leading to a more conservative outlook for NVIDIA's growth.
Potential of Local and Mobile Computing: The concentration of AI computing demand in data centers has benefited server and cloud computing companies. However, with advancements from companies like DeepSeek making AI models more efficient, there's potential for shifting this demand to local devices like PCs, tablets, and smartphones. Consumer electronics manufacturers such as Apple could see increased demand for AI-friendly consumer electronics, significantly broadening AI's application scope.



