DeepSeek:以创新算法和更低成本重塑AI领域


作者:Viga Liu
关键要点:
· 性能与成本:DeepSeek的R1模型在性能上与OpenAI的O1不相上下,特别在数学和编程领域表现出色,而DeepSeek通过创新算法实现了更具成本效益的训练。
· 算法创新:DeepSeek推出了如MOE、MLA、MTP和RL等开创性的方法,重新定义了AI模型开发的范式。
· NVIDIA的未来:DeepSeek的崛起正在重塑AI行业的估值格局,可能改变市场份额分布。短期内,NVIDIA的GPU仍占据主导地位,但DeepSeek的技术路线表明,未来通过算法优化可能减少对GPU的依赖。
DeepSeek近期发布的新模型凭借其在多项标准化测试中的亮眼表现,迅速成为人工智能领域的焦点,引发了业界的广泛关注。市场开始重新审视AI领域主要企业的股价,并深入探讨DeepSeek的创新可能带来的市场份额变动及技术路径调整,这也促使相关企业的市场估值得到重新评估。如下图所示,DeepSeek的R1模型在多个领域与OpenAI的O1模型表现不相上下,尤其在数学和编程任务中表现尤为突出。然而,在通用知识评估方面,DeepSeek-R1目前尚未实现对OpenAI O1模型的超越。
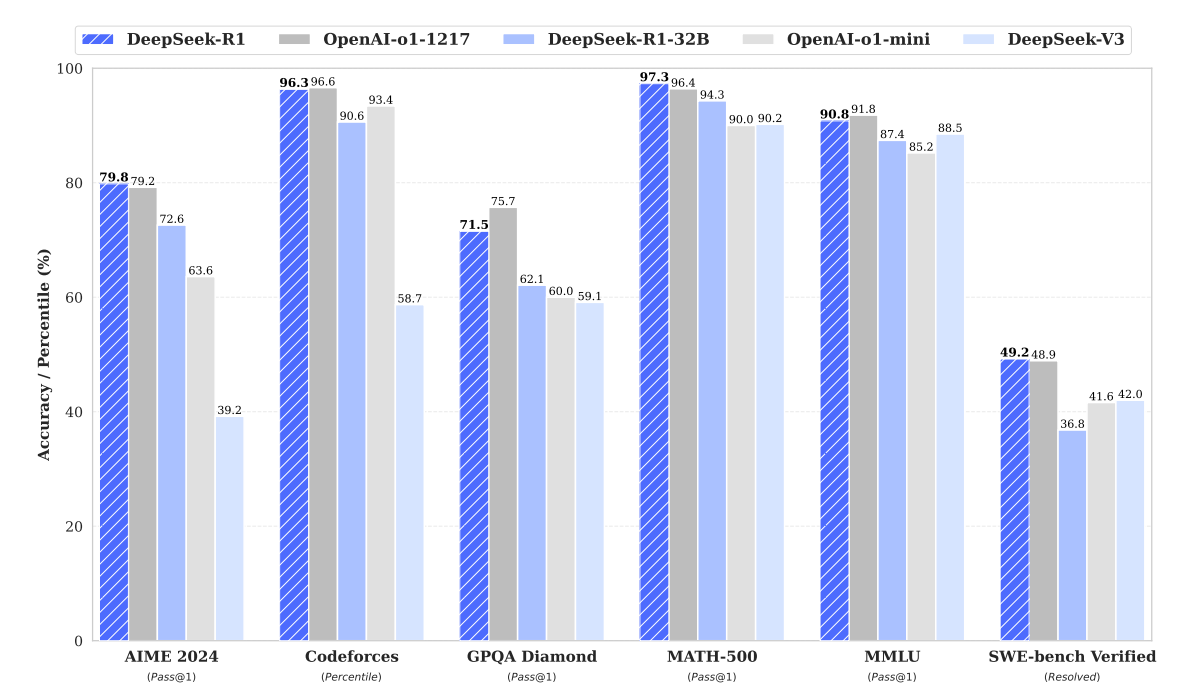
来源:DeepSeek
在数学竞赛AIME 2024上,DeepSeek-R1取得了79.8%的通过率,略高于OpenAI-oo1的79.2%,显示了其在数学推理方面的竞争力。在编程能力评估中,尽管DeepSeek-R1在Codeforces上达到了96.3%的表现,但仍稍逊于OpenAI-o1的96.6%,表明OpenAI的模型在编程任务中略占优势。在复杂数学问题集MATH-500的测试中,DeepSeek-R1以97.3%的准确率领先于OpenAI-o1的96.4%,凸显了其在数学领域的强劲实力。同样,在软件工程基准测试SWE-bench Verified中,DeepSeek-R1解决了49.2%的问题,略高于OpenAI-o1的48.9%,表明两者在特定工程任务中的表现旗鼓相当。然而,在通用知识测试MMLU中,DeepSeek-R1取得了90.8%的分数,虽接近但未超越OpenAI-o1的91.8%,反映出其在知识广度上仍存在一定差距。而在GPQA Diamond测试中,DeepSeek-R1以71.5%的准确率显著低于OpenAI-o1的75.7%,说明DeepSeek-R1在应对高级知识问题方面仍有提升空间。
更低的成本
从下表的模型对比中可以看出,DeepSeek V3在成本效益方面具有显著优势。其训练成本仅为558万美元,使用了2048块NVIDIA H800 GPU,耗时278万GPU小时。与其他模型相比,DeepSeek V3以极低的成本脱颖而出。这一成本效益的达成得益于其创新的算法优化和高效的资源利用,尤其是在DeepSeek V3并未采用最尖端GPU技术(H800并非最新一代产品)的情况下,这一成绩尤为引人注目。
根据行业分析公司SemiAnalysis创始人Dylan Patel整理的供应链数据,DeepSeek目前已经获得了约5万块NVIDIA芯片,其中包括被禁止出口到中国的H800。目前,尚未被禁运的H20 GPU可能成为H800的替代品,但尚无数据能够证明H20能否达到相同的性能和效率。如果H20同样面临美国的禁运,短期内将没有直接的芯片替代方案可供选择。

来源:Deepseek, OpenAI, Anthropic, SemiAnalysis, Tradingkey.com
来源:Deepseek
算法创新的分析
尽管DeepSeek在训练成本上表现出了显著的低成本优势,这一结果不可避免地引起了业界的一些质疑。为了揭开这一谜团,深入探讨DeepSeek算法的创新之处是必要的,以此来推论其如何在不牺牲性能的前提下实现成本的节约。
Mixture-of-Experts (MOE)架构
在传统的大型语言模型训练中,模型的每一部分都需要处理所有输入,无论这些输入是否适合其专业领域。这往往导致模型参数的过度使用或完全闲置,从而造成计算资源的浪费。模型可能需要巨大的计算能力来处理各种类型的数据,但实际上只有一小部分参数被真正用到。由于处理每个输入时所有参数都必须被激活,进一步扩展模型会因计算需求和内存占用的急剧增加而变得困难。这正是DeepSeek引入MOE架构的原因。
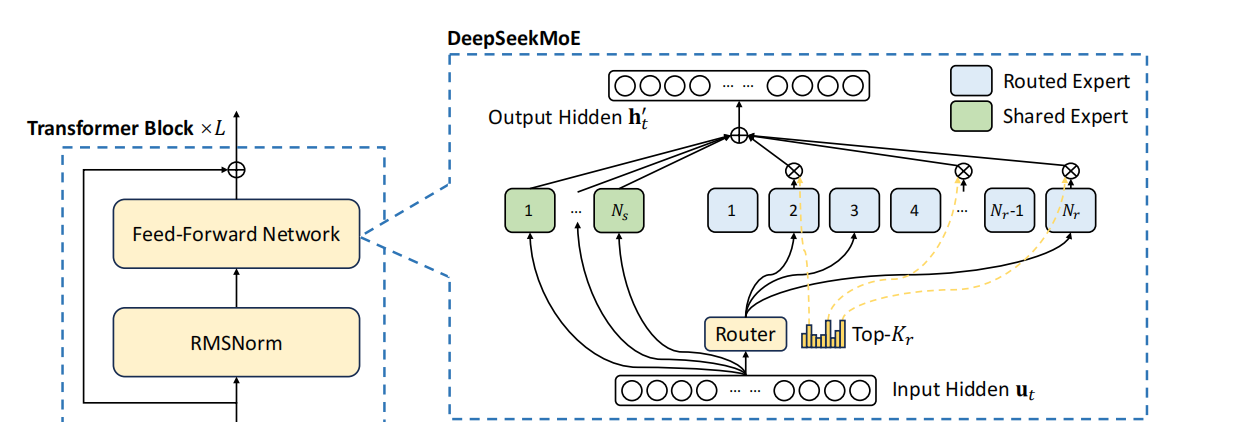
来源:DeepSeek
细粒度专家分割:DeepSeek通过将专家进一步细分为更小的单元,每个单元专注于特定的数据子集或任务,从而优化了其MOE架构。这样,每个小专家专注于一个较小的数据子集或任务,这意味着他们可以对其负责的特定领域进行更深入的学习和优化,而不是在所有数据上都表现平庸,同时避免了无效计算,提高了资源利用率。这意味着在相同的计算资源下,可以获得更高的模型性能。在大型模型中,单一专家网络处理所有类型的数据容易导致过拟合,因为它可能过于专注于学习数据中的噪音。通过细粒度分段,每个专家处理的只是数据的一部分,减少了过拟合的风险,因为他们更专注于捕捉特定领域的模式。通过细粒度专家分段,DeepSeek能够在不增加参数总数的前提下,提升模型的专业性和效率。
共享专家:DeepSeek的MOE架构中引入了共享专家,用于处理模型中共通的通用知识,这些知识不局限于特定任务。共享知识只需学习一次,便可被所有专家直接调用,避免了重复学习,从而加速处理过程并提升效率。。
负载平衡:负载平衡MOE架构中至关重要,它确保专家之间工作量的均匀分配。在其他MOE模型中,如果负载不均衡,某些专家可能几乎不被使用。传统上,负载平衡需要通过引入额外的损失函数来实现,这样做会增加模型的复杂性和计算开销,因为需要额外的计算来管理平衡。DeepSeek的方法减少了这部分开销。DeepSeek的创新在于它通过在Softmax层中引入偏置来动态调整每个专家的工作量分配。Softmax会给每个专家一个概率,概率高的专家更有可能处理当前的任务。偏置值会影响Softmax层的输出,使得那些负担过重的专家的概率稍微降低,而那些负担较轻的专家的概率稍微提高。在训练过程中,如果发现某个专家处理的tokens过多,可以通过Softmax层中的偏置降低这个专家的选择概率,使得tokens更均匀地分布到其他专家。通过这种方式,DeepSeek在不增加模型复杂度和计算开销的情况下,实现了有效的负载平衡,让每个专家都能得到合理的工作量,从而提高了模型的整体效率和资源利用率。
Multi-Head Latent Attention (MLA)
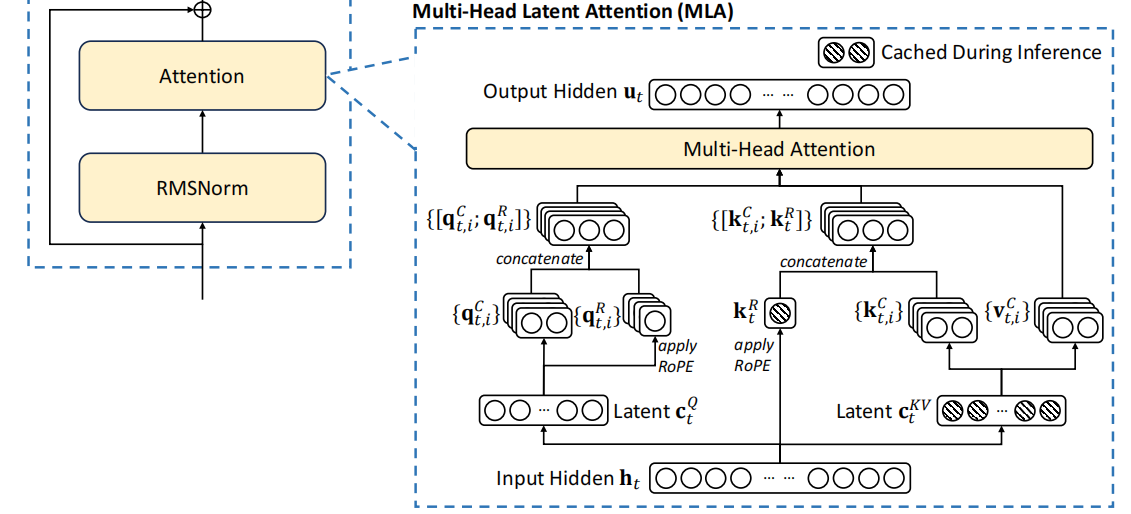
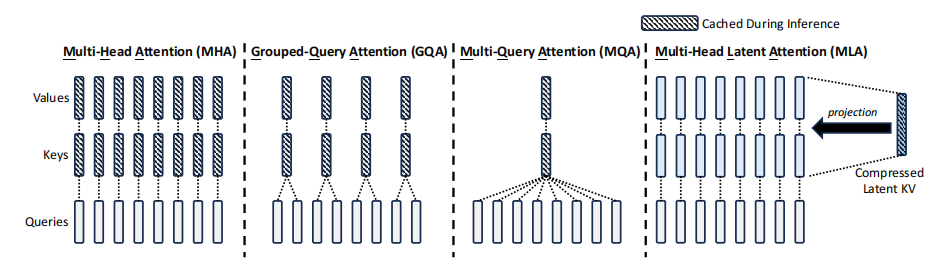
在传统的注意力机制中,模型相当于逐字阅读一本书,而MLA则是通过压缩信息来快速理解书的要点。DeepSeek开MLA的主要动机在于解决传统注意力机制在处理大规模数据时的几个关键问题。传统的多头注意力机制中需要存储每个token的K(键)、V(值),这在处理长文本或大批量数据时会导致巨大的内存需求KV缓存会变得非常庞大,占据大量的内存。在生成每个新token时,传统方法需要对所有前面的tokens进行计算,这大大增加了计算量,特别是在推理阶段。因为计算量大,传统模型在生成文本时速度较慢,尤其是在处理长序列时。
来源:DeepSeek
内存优化:通过低秩分解,MLA将Q(查询)、K(键)、V(值)矩阵压缩成更小的形式,显著减少了KV缓存的尺寸。在传统的多头注意力机制中,Q、K、V三个矩阵是完整的,高维度的。这意味着它们存储了所有可能的细节信息。低秩分解就像是将这三个矩阵拆分成更小的部分,这些部分组合起来能够近似表示原始矩阵,但只保留了最重要的信息,减少了存储需求。
来源:DeepSeek
潜在空间压缩:将信息从高维度压缩到低维度,原始的K和V被映射到一个低维度的“潜在空间”,在这个空间中,数据的表示更简洁但仍然包含了关键信息。压缩后的数据更易处理,减少了计算量。矩阵乘法等操作在低维空间中进行,计算速度显著提高。
Rotary Positional Embedding, RoPE:位置信息在文本处理中至关重要。传统模型在数据压缩或简化后可能会丢失这一信息,因为它们依赖于详细且固定的位置编码。DeepSeek将RoPE集成到其MLA机制中,以确保即使在数据压缩后,模型仍能理解位置信息。RoPE通过旋转矩阵对位置信息进行编码,其中每个token的位置由旋转角度表示,而这一角度随位置变化。这种方法能够在压缩空间中捕捉“词与词之间的距离”,而无需为每个位置存储位置向量,从而优化了内存使用并降低了计算复杂度。在生成新token时,RoPE通过保留上下文中的位置关系,帮助模型更准确地预测下一个词的位置。
Multi-Token Prediction (MTP)
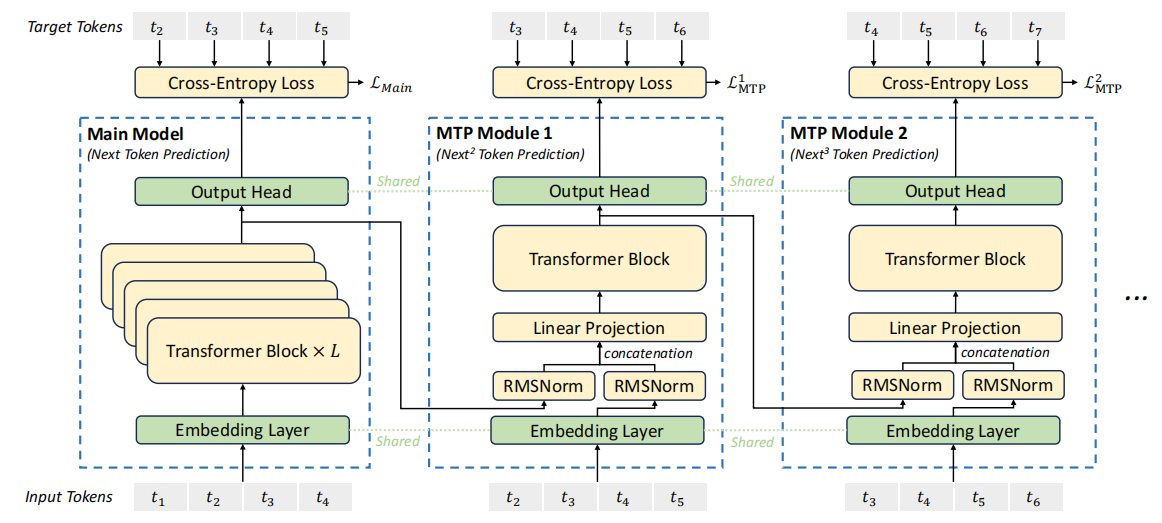
大语言模型通常是自回归,即一次只生成一个token,一轮训练或推理需要进行多次操作才能完成对一句话或一段文字的处理,训练过程缓慢。DeepSeek创新的MTP改变了传统的训练和推理方式。
来源:DeepSeek
并行预测:每一个训练步骤,模型同时预测多个未来的tokens,而不是一个。这减少了训练步骤,因为一轮训练可以处理更多的信息。
Speculative Decoding:预先生成多个可能性并快速验证,减少了等待时间,来优化推理速度。在验证过程中,模型可能使用之前已经计算好的信息(KV缓存),避免重复计算,提高速度。
Mask机制:通过在注意力层中使用mask,确保模型在预测未来tokens时,不能看到那些tokens后面的内容,维持了序列的因果关系。
Reinforcement Learning (RL)
Supervised Fine-Tuning (SFT)是训练语言模型的一个常见方法,通过标注数据对预训练的语言模型进行进一步训练,在OpenAI的模式中,SFT是post-training的一部分。首先进行大规模的预训,然后通过SFT来细化模型的输出,使其更符合特定任务的需求。接着,可能会使RL进行模型的对齐,以确保模型的输出符合人类的偏好。DeepSeek提出了一种新的后训练方法,认为在增强模型的推理能方面,SFT并非必要,而直接使用RL。
替代SFT:模型通过与环境的互动来学习和改进,而不是依赖于人工标注的大量数据。这减少了对数据收集和标注的依赖,减少了数据标注过程中的劳动力成本。
Multistage Training:采用了多阶段的训练策略,先进行大规模的预训练,然后利用RL进行后期的优化。这种方法允许在不同阶段利用不同类型的学习机制,增强模型的推理和理解能力。
冷启动数据:使用已有的模型生成数据来训练新的模型或增强现有模型。这是一种通过Bootstrapping来扩展数据集的方法,减少了对外部新数据的依赖,降低了数据成本。
挑战Scaling Law:传统上模型的性能通常会随着模型规模的线性或近似线性增长,即规模越大,性能通常越好,但这种增长趋势是有限的,可能会达到一个饱和点。但DeepSeek的R1模型通过RL展示了涌现能力,随着模型规模的增加,某些能力或性能会突然或非线性地显著提升,而不是简单地逐步改善。这些能力在较小的模型中可能表现得并不明显,但在大规模模型中突然涌现出惊人的效果。
DeepSeek的创新在于它不仅仅通过增加模型规模来提升性能,还通过不同的学习方法(如RL)来激发模型潜在的能力。这种方法可能在传统的Scaling Law中没有被充分考虑。如果性能的提升不是线性的,那么在一定的规模下,通过创新的训练方法,可能不需要无限增加模型规模就能获得显著的性能提升,这对于资源利用效率有着积极的影响。DeepSeek的创新不仅带来了性能上的突破,还提供了更具成本效益的策略,使人工智能开发更加普及。这对投资者和AI从业者来说无疑是一个好消息。
值得关注的是DeepSeek的技术创新不是凭空而来,而是建立在Google、Meta以及学术界多年研究的基础之上。但DeepSeek针对需求进行了独特优化。他们在模型架构、训练和推理方面进行了系统性改进。例如,DeepSeek对谷歌的“Switch Transformers”中MOE进行了优化,采用了细粒度的专家分割和共享隔离机制。同时,受Meta的“Reformer”启发,DeepSeek开发MLA通过潜在空间压缩和低秩分解解决了内存问题。这些创新激发了行业内对算法研究的进一步兴趣,我们可以预见,在不久的将来,更多高效的人工智能模型将涌现。开源模型类似Meta的Llama等可能会采用类似的算法,从而推动AI技术的进一步发展。
OpenAI对模型蒸馏的指控
在讨论DeepSeek的成本优势时,OpenAI提出了一种可能性,即DeepSeek可能采用了模型蒸馏技术。这种方法通过从一个大型、复杂的“教师”模型中提炼知识到一个较小、更高效的“学生”模型中,以实现性能的保留和计算资源的节约。DeepSeek尚未对这一问题做出回应。如果OpenAI基于这一怀疑决定不给DeepSeek提供API访问权限,那么DeepSeek的模型训练和推理过程可能受到影响。
即便OpenAI限制DeepSeek的访问, DeepSeek已经通过其独特的算法创新,展示了其可以在不依赖外部模型数据的情况下,实现高效训练和推理的能力,尽管会制造些困难,但对模型的进一步开发并不会因此完全停滞。
绕过NVIDIA CUDA的可能
DeepSeek已经在实践中实施了通过定制的PTX(Parallel Thread Execution)指令和自动调优通信块大小的优化方法。这一策略的核心在于绕过CUDA的高级接口,直接与GPU的底层硬件进行交互。CUDA通常提供了更高层次的抽象,使得开发者可以更容易地编写GPU加速的程序,CUDA会通过编译器将代码转换为PTX,然后再由GPU硬件执行。DeepSeek通过直接使用PTX指令,能够绕过这一层抽象,从而实现对硬件资源的更精细控制,减少了不必要的中间步骤,实现高效的模型训练和推理。
尽管如此,短期内还是没有办法完全脱离NVIDIA的生态系统,CUDA已经成为了GPU编程的事实标准,广大开发者已经适应此生态,转向非NVIDIA的GPU确实需要重建软件堆栈,耗时间也费钱,特别是在没有CUDA的情况下要达到类似的性能。
对NVIDIA的影响
短期影响:NVIDIA在AI计算领域仍然占据主导地位。例如,现在虽然可以在Amazon Bedrock和Amazon SageMaker AI中部署DeepSeek-R1模型,但NVIDIA的GPU仍然在这些平台上扮演着关键角色,显示了短期内对其硬件的持续依赖。像Meta、微软、谷歌和亚马逊这样的科技巨头计划在2025年大幅增加AI资本支出,其中Meta预计为600-650亿美元,微软为800亿美元,谷歌为750亿美元(其中30%用于NVIDIA GPU),亚马逊为1000亿美元。这强调了对于高性能计算资源的持续需求,特别是在数据中心端,NVIDIA的GPU在性能、生态系统支持和市场认可度上都处于领先地位,这意味着在AI计算需求继续增长的背景下,NVIDIA的市场份额和股价在短期内不会受到重大威胁。
算法优化的影响:从长远来看,DeepSeek展示的通过算法优化来提升AI模型效率的策略,确实可能对NVIDIA产生负面影响。如果大厂商转向通过优化算法而不是单纯增加计算能力来实现AI性能的提升,这将减少对高端GPU的需求。特别是当开源和创新算法被广泛采用时,市场对NVIDIA专有硬件的依赖可能会减弱。虽然目前各大厂商声称不会减少对算力资源的投资,但随着时间的推移,市场对算GPU制造商的选择范围扩大,可能会导致NVIDIA的市场份额逐渐受到侵蚀。
市场对未来增长的预期:NVIDIA目前股价的估值是基于对2025年强劲增长的预期,EPS增长预测在30%-50%之间。低于这一水平的业绩都可能使其股价下调。市场对2025年之后增长轨迹可持续性的担忧日益加剧,摩根士丹利将NVIDIA GB200的出货量预测从3万至3.5万件下调至2万至2.5万件,这可能对市场产生300亿至350亿美元的影响。这一调整反映了市场对微软资本支出增长放缓、AI基础设施生态系统的发展以及关于大语言模型长期效率问题的担忧,导致对英伟达增长前景的看法更加保守。
本地计算与移动端的潜力: 由于AI计算需求之前集中在数据中心,服务器和云计算公司因此受益。但随着如DeepSeek等公司推动AI模型变得更加高效,有可能将这一需求转移到本地设备,如个人电脑、平板电脑和智能手机。这种转变意味着AI不再只是数据中心的专利,而是可以普及到消费者手中。苹果等消费电子厂商,如果AI模型能在其设备上提供引人注目的功能,这将极大地扩大AI的使用范围,增加对高效、AI友好的消费类设备的需求。