

Mark Zuckerberg CEO ของ Meta อนุมัติการใช้หนังสือละเมิดลิขสิทธิ์เพื่อฝึกอบรม AI: การยื่นฟ้องของศาล

Meta Platforms ฝึกฝนโมเดล AI โดยใช้หนังสือลิขสิทธิ์เวอร์ชันละเมิดลิขสิทธิ์ โดยได้รับอนุมัติจาก Mark Zuckerberg ซีอีโอ
ตามเอกสารของศาลที่เพิ่งเปิดเผย กลุ่มนักเขียนกล่าวหาว่าโซเชียลมีเดียยักษ์ใหญ่รู้ว่าพวกเขากำลังใช้งานละเมิดลิขสิทธิ์เพื่อฝึกระบบ AI ของพวกเขา
เอกสารภายในจาก Meta “เปิดเผย” ข้อเรียกร้อง
ในการยื่นฟ้องต่อศาล ผู้เขียนกล่าวว่าเอกสารภายในที่ Meta จัดทำในระหว่างกระบวนการค้นพบแสดงให้เห็นว่าบริษัทเครือข่ายโซเชียลทราบเกี่ยวกับหนังสือละเมิดลิขสิทธิ์ ตามรายงานของ The Guardian ซีอีโอ Zuckerberg สนับสนุนการใช้ชุดข้อมูล LibGen ซึ่งเป็นคลังหนังสือออนไลน์ขนาดใหญ่ แม้จะมีคำเตือนภายในทีมผู้บริหาร AI ของบริษัทว่าเป็นชุดข้อมูล “เรารู้ว่าถูกละเมิดลิขสิทธิ์”
ทา-เนฮิซี โคตส์ นักเขียนชาวอเมริกัน, นักแสดงตลก ซาราห์ ซิลเวอร์แมน และนักเขียนคนอื่นๆ ที่ฟ้องร้องบริษัทเรื่องการละเมิดลิขสิทธิ์ ได้ร่วมกันกล่าวหาในเอกสารที่ยื่นต่อสาธารณะเมื่อวันพุธที่ศาลรัฐบาลกลางของรัฐแคลิฟอร์เนีย
ผู้เขียนนำ Meta ขึ้นศาลในปี 2023 โดยมีข้อกล่าวหาว่าบริษัทโซเชียลมีเดียใช้หนังสือของตนในทางที่ผิดเพื่อฝึกโมเดล AI โดยเฉพาะ Llama ซึ่งเป็นโมเดลภาษาขนาดใหญ่ที่ขับเคลื่อนแชทบอท
ชุดข้อมูล Library Genesis หรือ LibGen ซึ่งมีต้นกำเนิดในรัสเซียคือ "ห้องสมุดเงา" ซึ่งอ้างว่ามีนวนิยาย หนังสือแจ้งเตือน และบทความในนิตยสารวิทยาศาสตร์หลายล้านเล่ม
ในปี 2024 ศาลรัฐบาลกลางนิวยอร์กขอให้ผู้ดำเนินการที่ไม่ระบุตัวตนของ LibGen จ่ายค่าเสียหายให้กับกลุ่มผู้จัดพิมพ์จำนวน 30 ล้านดอลลาร์ สำหรับการละเมิดลิขสิทธิ์
นี่เป็นหนึ่งในหลายๆ เรื่องที่กล่าวหาว่างานที่มีลิขสิทธิ์ของผู้เขียน ศิลปิน และคนอื่นๆ ถูกนำมาใช้ในการฝึกอบรมเครื่องมือ AI เชิงสร้างสรรค์ เช่น แชทบอท ChatGPT โดยไม่ได้รับความยินยอมจากเจ้าของ ผู้เชี่ยวชาญด้านการสร้างสรรค์ได้เตือนว่าการใช้งานโดยไม่ได้รับความยินยอมกำลังเป็นอันตรายต่อรูปแบบธุรกิจของตน
ตามรายงานของ Reuters จำเลยได้โต้แย้งว่าพวกเขาใช้เนื้อหาที่มีลิขสิทธิ์โดยชอบธรรม
ผู้พิพากษาอนุญาตให้ผู้เขียนยื่นคำร้องที่มีการแก้ไขเพิ่มเติมได้
ในกรณี Meta มีรายงานว่าผู้เขียนได้ขออนุญาตจากศาลเมื่อวันพุธเพื่อยื่นคำร้องเรียนที่อัปเดต ในการโต้แย้ง พวกเขาระบุว่าหลักฐานใหม่แสดงให้เห็นว่าบริษัทเครือข่ายโซเชียลใช้ชุดข้อมูลการฝึกอบรม AI LibGen ซึ่งรวมถึงผลงานละเมิดลิขสิทธิ์หลายล้านชิ้น และเผยแพร่ผ่านทอร์เรนต์แบบ peer-to-peer
ตามที่พวกเขากล่าว Zuckerberg “อนุมัติการใช้ชุดข้อมูล LibGen ของ Meta แม้ว่าจะมีข้อกังวลภายในทีมผู้บริหาร AI ของ Meta (และคนอื่นๆ ที่ Meta) ว่า LibGen นั้นเป็น 'ชุดข้อมูลที่เรารู้ว่าถูกละเมิดลิขสิทธิ์'”
เอกสารดังกล่าวยังอ้างถึงบันทึกช่วยจำที่อ้างอิงถึงชื่อย่อของ Zuckerberg โดยระบุว่า "หลังจากการยกระดับเป็น MZ" ทีม AI ของ Meta "ได้รับการอนุมัติให้ใช้ LibGen"
เมื่อปีที่แล้ว Vince Chhabria ผู้พิพากษาเขตของสหรัฐอเมริกา ยกฟ้องข้อกล่าวหาว่าข้อความที่สร้างโดยโมเดล AI ของ Meta ละเมิดลิขสิทธิ์ของผู้เขียน และ Meta ได้ลอกข้อมูลการจัดการลิขสิทธิ์ของหนังสืออย่างผิดกฎหมาย หมายถึง ข้อมูลเกี่ยวกับผลงาน ได้แก่ ชื่อเรื่อง ชื่อผู้แต่ง และเจ้าของลิขสิทธิ์
อย่างไรก็ตาม โจทก์ได้รับอนุญาตให้แก้ไขข้อเรียกร้องของตนได้ ในการโต้แย้งในสัปดาห์นี้ ผู้เขียนกล่าวว่าหลักฐานสนับสนุนการเรียกร้องการละเมิดของพวกเขา และให้เหตุผลในการรื้อฟื้นคดีข้อมูลการจัดการลิขสิทธิ์ของพวกเขา โดยเพิ่มข้อกล่าวหาเรื่องการฉ้อโกงคอมพิวเตอร์ใหม่
ในระหว่างการพิจารณาคดีเมื่อวันพฤหัสบดี ผู้พิพากษากล่าวว่าเขาจะอนุญาตให้ผู้เขียนยื่นคำร้องที่มีการแก้ไข แม้ว่าเขาจะไม่เชื่อเกี่ยวกับข้อดีของการฉ้อโกงดังกล่าวก็ตาม
ได้งาน Web3 ที่จ่ายสูงใน 90 วัน: สุดยอดโรดแมป
บทความที่เกี่ยวข้อง
การคาดการณ์หุ้น Amazon ปี 2026 ถึง 2030: จะสามารถทำผลงานเหนือความคาดหมายและบรรลุเป้าหมายระยะยาวที่สำคัญได้หรือไม่?
TradingKey - เมื่อก้าวเข้าสู่ปี 2026 นักลงทุนจำนวนมากต่างตั้งคำถามถึงบทบาทของ Amazon (AMZN) ในโลกเทคโนโลยี
3 แผนภูมิสะท้อนภาพการเปลี่ยนแปลงของราคาทองคำและเงิน
TradingKey - ราคาทองคำและเงินฟื้นตัวขึ้นในวันพุธหลังจากถูกเทขายอย่างหนักเมื่อสัปดาห์ที่แล้ว โดยนักลงทุนในกลุ่มโลหะมีค่าดังกล่าวยังคงมีความเชื่อมั่น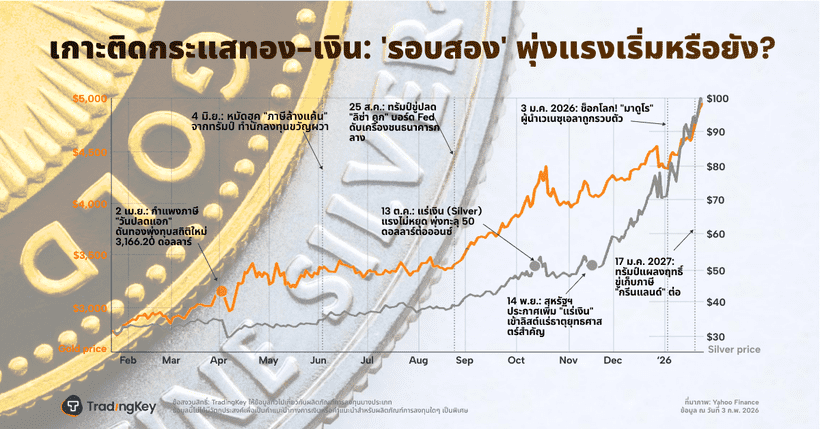
ราคาทองคำและเงินฟื้นตัวอย่างแข็งแกร่ง: การฟื้นตัวในระยะสั้นหรือจุดเริ่มต้นของตลาดขาขึ้นรอบใหม่?
TradingKey - โลหะมีค่าดีดตัวกลับอย่างแข็งแกร่งหลังความผันผวนอย่างรุนแรง ในขณะที่ตลาดกำลังเผชิญกับการเลือกทิศทางที่สำคัญ หลังจากปรับตัวลดลงอย่างหนักติดต่อกันสองวัน ตลาดโลหะมีค่าได้กลับมาฟื้นตัวอย่างแข็งแกร่งในวันอังคารนี้ โดยเมื่อวันที่ 3 สัญญาซื้อขายทองคำและเงินล่วงหน้าในตลาดนิวยอร์กปิดตลาดพุ่งสูงขึ้นอย่างมีนัยสำคัญ ส่งผลให้บรรยากาศการลงทุนปรับตัวดีขึ้นอย่างเห็นได้ชัด นักลงทุนกำลังประเมินความตื่นตระหนกที่เกิดขึ้นก่อนหน้านี้จากปัจจัยทางนโยบายใหม่ และกำลังมองหาโอกาสในการเข้าซื้อเมื่อราคาอ่อนตัว (buy-the-dip) อย่างคึกคัก
VOO หุ้นเด่น: กองทุน ETF S&P 500 ของ Vanguard เปรียบเทียบกับ VUG และ QQQ สำหรับนักลงทุนระยะยาว
TradingKey - กองทุน ETF Vanguard S&P 500 (VOO) เป็นหลักทรัพย์ยอดนิยมที่นักลงทุนเลือกถือมาอย่างยาวนาน เพื่อเข้าถึงหุ้นสหรัฐฯ ในวงกว้าง เมื่อมีผู้คนหันมาลงทุนแบบ Passive และสนใจ “กองทุน ETF Vanguard ที่ดีที่สุด” มากขึ้น การถกเถียงระหว่าง VOO, กองทุน ETF Vanguard Growth (VUG) และ Invesco QQQ Trust (QQQ
SanDisk (SNDK) หุ้นยักษ์ใหญ่ Flash Memory: เจาะลึกปัจจัยหนุนการปรับตัวขึ้น และยังน่าซื้ออยู่หรือไม่?
TradingKey ยังคงมองเห็นศักยภาพการเติบโตระยะยาวของ SanDisk แต่เตือนนักลงทุนไม่ให้คาดหวังราคาหุ้นระยะสั้นที่สูงเกินไปนัก เนื่องจากอัตราการปรับขึ้นในอนาคตมีแนวโน้มชะลอตัวลงอย่างมาก ดังนั้น กลยุทธ์ที่รอบคอบกว่าคือการรอมูลค่าหุ้นมีการปรับฐาน และรอการยืนยันถึงวัฏจักรขาขึ้นของอุตสาหกรรมที่ยั่งยืนก่อนเข้าลง
